SplitFed: When Federated Learning Meets Split Learning
본문: https://arxiv.org/pdf/2004.12088.pdf
1. Split Learning

split learning은 client의 private data에 대한 유출을 막고 storage 비용을 최소화 하면서 고성능의 ML 모델을 얻을수 있는 방법론 입니다. 위 그림은 다양한 Split learning의 일부를 보여주고 있습니다. (a)의 바닐라 SL의 경우에는 중간레이어 값을 전송값으로 하는 통신 과정을 보여줍니다. 이때 전송 레이어를 smashed data라고 표현합니다.
(b)는 U shape SL을 보여줍니다. (a)의 경우에는 smashed data와 함꼐 현재 훈련중인 데이터의 label을 전송했어야 했습니다.
하지만 label에 Private data가 담겨 있는 경우를 감안할떄 최종 layer를 다시 시작 client로 보내 라벨에 대한 유출을 막는것 또한 합리적입니다.
FL이 모든 model의 trainable parameter를 전송하는 형태였다면 SL은 모델의 일부만을 전송해 훈련합니다. 이과정은 1:1로 매핑되어 있습니다. 이와 같은 구조를 갖는 경우 Edge device의 한계를 극복하고 기존 FL에서 수행하지 못했던 대규모 신경망에 대한 추론을 가능하게 한다는 점이 또다른 특징입니다.
다만 SL은 병렬로 훈련을 수행할 수 없습니다. 서버 측에서 하나의 잔여 대규모 신경망의 일부를 보유하고 있으므로 각 client와 훈련하기 위해서는 1:1로 매핑되어 훈련해야 합니다. 이는 non-IID를 가정하거나 client가 소규모 데이터를 갖는 경우에 spoil이 일어날 가능성이 높습니다.
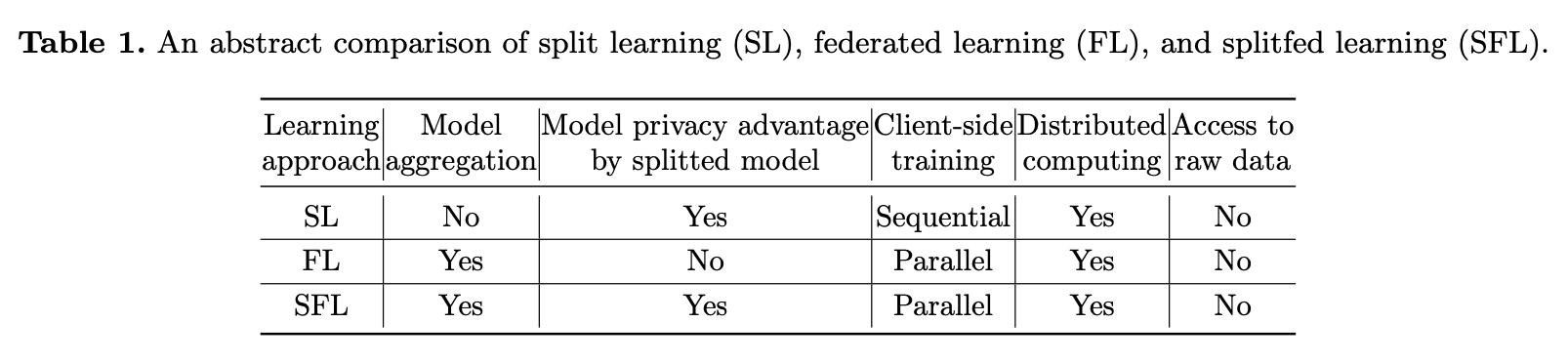
위 표는 FL SL 의 특징을 간략하게 설명합니다. SL은 다양한 client의 데이터를 훈련하기 위해서는 Sequential 하게 훈련된다는 점을 주목합니다.
2. SplitFed

이 페이퍼에서는 SL을 위한 서버와 FL을 위한 서버 2개를 차용합니다. client는 신경망의 일부를 갖고 main server와 통신하며 SL을 수행합니다. 그 과정에서 SL의 Sequential training의 한계를 극복하기 위해 각 client에 1:1로 매핑되는 신경망의 복사본을 main server에 유지합니다. 그리고 잔여 layer에 대한 Weighted Summation을 수행하고 다시 재 배포 합니다.
이는 SL의 한계를 극복하고 상대적으로 병렬적인 훈련을 가능하게 합니다. 하지만 맹점은 Main Server에서 진정으로 병렬 훈련이 일어나기 위해서는 독립된 메모리공간을 할당하고 서로 다른 device에서 훈련하거나 자원을 공유 합니다. 하지만 다양한 paper의 실험 결과에서도 알 수 있듯이 training device를 공유하면 훈련 속도는 비선형적으로 감소하기 때문에 진정한 의미에서의 병렬 훈련이라고 볼수 없습니다.


이 과정은 위와 같이 표현됩니다.
모든 클라이언트는 노이즈 레이어(smashed data)를 통해 클라이언트 측 모델에서 병렬로 순방향 전파를 수행하고 스매싱된 데이터를 메인 서버로 전달합니다. 그런 다음 메인 서버는 각 클라이언트의 분쇄된 데이터를 (다소) 병렬로 개별적으로 사용하여 서버 측 모델에서 순방향 전파 및 역방향 전파를 처리합니다. 그런 다음 역전파를 위해 스매싱된 데이터의 기울기를 각 클라이언트로 보냅니다. 그 후 서버는 FedAvg로 모델을 업데이트합니다. 즉, 각 클라이언트의 smashed 데이터에 대한 역전파 중에 계산하는 그래디언트의 가중 평균입니다. 클라이언트 측에서 스매싱된 데이터의 기울기를 수신한 후 각 클라이언트는 클라이언트 측 로컬 모델에서 역전파를 수행하고 기울기를 계산합니다. DP 메커니즘은 이러한 그라디언트를 비공개로 만들고 공급 서버로 전송하는 데 사용됩니다. Fed 서버는 클라이언트 측 로컬 업데이트의 FedAvg를 수행하고 모든 참여 클라이언트로 다시 보냅니다.
FL이 대규모 client를 동시에 훈련하는 것을 목표로 하고 있습니다. 만약 동시에 훈련 할 수 있는 client가 늘어난다면 서버에 상당한 부하가 우려됩니다.
SplitFed의 변형
SFL에는 여러 변형이 있을 수 있습니다만 여기서는 이를 다음과 같은 두 가지 범주로 크게 나눕니다.
서버 측 집계를 기반으로 할때 SFL의 두 가지 버전이 있습니다.
첫 번째는 splitfedv1(SFLV1)이라고 하는데 알고리즘 1과 2에 묘사되어 있습니다. 다른 알고리즘은 splitfedv2(SFLV2)라고 하며 모델 집계 부분을 제거하여 모델 정확도를 높일 수 있다고 주장합니다.
알고리즘 1의 서버 측 계산 모듈에서. 알고리즘 1에서 모든 클라이언트의 서버 측 모델은 개별적으로 (비교적) 병렬로 실행된 다음 각 global iteration에서 FedServer에 의해 집계됩니다.
반대로 SFLV2는 클라이언트의 스매싱 데이터 (즉 서버 측 모델의 FedAvg 없음)를 서버 측 모델의 정방향 전파를 순차적으로 처리합니다.
이과정은 서버의 부하를 줄일 수 있으나 진정한 병렬훈련에서 벗어나 있습니다.
클라이언트 순서는 서버 측 작업에서 무작위로 선택되며 모델은 매 순방향 전파에 의해 업데이트됩니다.
또 서버는 모든 참여 클라이언트로부터 스매싱된 데이터를 동기적으로 수신합니다. 클라이언트 측 작업은 SFLV1에서와 동일하게 유지되지만 결과를 집계하는것은 순차적입니다. (병렬 + Sequential).
Fed 서버는 클라이언트 측 로컬 모델의 FedAvg를 수행하고 집계된 모델을 모든 참여 클라이언트로 다시 보냅니다. 이러한 작업은 로컬 클라이언트 측 모델이 가중 평균 방법(즉, FedAvg)에 의해 집계되기 때문에 클라이언트 주문의 영향을 받지 않습니다.
이 버전은 최상단 그림의 (a)와 같이 데이터 레이블 공유를 기반으로 합니다.
만약 데이터 레이블을 공유하지 않는 경우를 가정하면 SFL의 ML 모델을 세 부분으로 분할할 수 있습니다.
각 클라이언트는 두 개의 클라이언트 측 모델 부분을 처리합니다. 하나는 W의 처음 몇 개의 레이어가 있고 다른 하나는 W의 마지막 몇 레이어와 손실 계산이 있습니다. W의 나머지 중간 레이어는 서버 측에서 계산됩니다.

위 표는 훈련 비용을 산정한 표 입니다. 전체 comm에 비례해서 (K만큼) 증가하는것을 확인할 수 있습니다.
하지만 training time에서 T_fedavg가 절반이라는 점은 서버측의 집계 과정을 배제 했기 때문입니다.
3. Experiment Result



