CPSL : __Split Learning over Wireless Networks: Parallel Design and Resource Management__
본문 :
SL(Split Learning)은 신경망 모델을 컷레이어에서 기기 측 모델과 서버 측 모델로 분할하여 기기와 에지 서버 사이에서 학습할 수 있는 분산 학습 프레임워크라고 이 전 포스트에서 알아보았습니다.
기존 SL 접근 방식은 장치 간에 순차적으로 훈련 프로세스를 수행하므로 특히 장치 수가 많을 때 상당한 훈련 대기 시간이 발생합니다. 특히나 서버측에서 클라이언트의 상태에 대한 어떠한 정보를 알지 못하므로 하나의 client가 훈련 중에 있을때 다른 잔여 client는 전부 유휴 상태에 돌입합니다.
이에 이 논문 에서는 훈련 대기 시간을 줄이기 위해 "최초 병렬 후 순차" 방식으로 모델 훈련을 수행하는 CPSL(Cluster-based Parallel SL)를 제안합니다.
CPSL은 client를 여러개의 클러스터로 분할하고 각 클러스터에서 장치 측 모델을 병렬로 훈련하고 집계한 다음 클러스터 전체에서 전체 신경망 모델을 순차적으로 훈련하여 훈련 프로세스를 병렬화해서 훈련 대기 시간을 줄입니다.

이전 포스트와 그림과 같이 SL의 기본 아이디어는 컷 레이어의 신경망 모델을 client에서 실행되는 장치 측 모델과 서버에서 실행되는 서버 측 모델로 분할하는 것입니다.
SL의 process는 간단합니다.
먼저 장치는 로컬 데이터로 장치 측 모델을 실행하고 컷 레이어와 관련된 중간 출력, 즉 스매싱 데이터를 서버로 보낸 다음 에지 서버는 서버 측 모델을 실행하여 순방향 전파를 수행합니다.
두 번째로, 서버는 서버 측 모델을 업데이트하고 컷 레이어와 관련된 스매싱된 데이터의 기울기를 client로 보낸 다음 client가 client 측 모델을 업데이트하여 BP(Backward Propagation) 프로세스를 수행합니다.

실제로 신경망을 훈련하기 위한 feature training 연산의 대부분은 모델의 후반부에서 일어나고 전반부에서는 feature extraction이 일어납니다.
trainable parameter의 size 또한 Fully connected layer가 대부분 인 것으로 미루어 보았을때 서버 측에서 FC연산을 수행한다면 client 부하를 줄일 수 있습니다.
즉 SL에서는 작은 크기의 장치 측 모델, 스매싱 데이터, 스매싱 데이터의 기울기만 전송하므로 통신 오버헤드가 줄어든다는 의미입니다.
일부 모델로 인해 신경망의 일부만 훈련하므로 계산 워크로드 또한 감소 합니다. 위 그림 처럼 LeNet 예에서 FL과 비교하여 컷 레이어 POOL1이 있는 SL은 통신 오버헤드를 16.49MB에서 0.35MB로 97.8% 줄이고 계산 워크로드를 91.6MFlops에서 5.6MFlops로 93.9% 줄입니다.
CPSL

Initialize stage
초기화 단계에서는 모델 파라미터를 무작위로 초기화하고, 학습 대기 시간을 최소화하기 위한 최적의 컷 레이어를 선택합니다. (아래에서 서술)
초기화 후 CPSL은 최적의 model parameter가 식별될 때까지 연속적으로 training round를 수행합니다.
하나의 훈련 라운드에 참여하는 모든 장치는 정적 장치 채널 조건 및 컴퓨팅 기능이 있는 Access Point의 커버리지 영역에 머문다고 가정해 안정적인 훈련 절차를 수행한다고 간주합니다.
각 훈련 라운드 $t ∈ T = {1,2,...,T}$에서 훈련 절차는 아래와 같이 수행됩니다.
Intra cluster training stage

이 단계에서 AP는 참여 client의 컴퓨팅 기능 및 채널 상태에 대한 실시간 정보를 수집한 다음 client를 여러 클러스터로 분할합니다. client 클러스터링 의사 결정 알고리즘은 위와 같습니다. $m$은 클러스터 수를 나타내고 $M$은 클러스터 집합입니다. 클러스터의 장치 집합은 $K_m, ∀m ∈M$으로 정의 됩니다.
만약 $n ̸= m$이면 $∪M_m=1 K_m =N$이고 $Kn∪Km =∅$이 되는셈 입니다.
Device-side model distribution
이 단계에서 AP는 초기 클러스터 $m$의 모든 참여 장치에 대해 $w_m^d(t)$로 정의되는 신경망 모델을 배포합니다. 그리고 $l ∈ L = {1, 2, ..., L}$ 동안 훈련합니다. 이때 첫번째 local epoch에서

모든 참여 client는 같은 모델을 공유 하게 됩니다.
Device-side model execution
이 단계에서 각 client는 랜덤하게 선택된 무작위 미니 배치를 구성합니다. $B_{m,k}(t,l) ⊆ D_{m,k}$는 전체 데이터의 일부로 정의 됩니다. 따라서 이 paper에서는 data bias는 고려하지 않습니다.
그리고 배포된 모델에 대한 일부 순전파를 수행하면 다음과 같은 결과를 얻을 수 있습니다.

Server-side model execution
서버는 모델의 일부에 대한 smashed data를 concat 하고 하나의 입력 집합

으로 만듭니다.
그리고 상대적으로 순차적으로 실행되는 model train을 수행합니다.

이에 모델 업데이트는 client에서 공유된 label을 따라 다음과 같이 수행됩니다.

Device-side model update
그러면 client에서는 수신된 smashed data’s gradient를 통해 다음과 같이 잔여 업데이트를 수행합니다.

Model aggregation
그후 서버에서는 device의 model을 집계하고 업데이트 합니다.
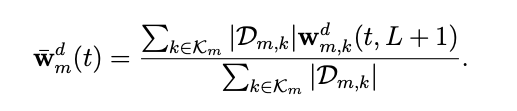
Simulation result

실험결과 제안된 방식은 더 많은 훈련 라운드 비용으로 동작하는 CL 및 SL과 거의 동일한 정확도를 달성하고 있습니다.
이는 각 클러스터의 장치 측 모델 집계가 모델 수렴 속도를 늦추기 때문입니다.
다시 말해, 제안된 방식은 수렴하는 데 상대적으로 다수번의 훈련 라운드가 필요합니다.

또 FL은 많은 수의 장치 간의 모델 집계로 인해 다른 알고리즘보다 훨씬 느리게 수렴됩니다.
또한 client side의 계산 워크로드로 인해 FL은 수렴 전에 훈련 지연 시간이 길어집니다.
제안하는 CPSL은 convergence에 도달하는 데 SL보다 짧은 시간이 걸리고 있습니다.
CPSL이 소모하는 시간은 약 600초인 반면, SL은 약 1,400초입니다.
그 이유는 제안하는 방식의 라운드당 훈련 대기 시간이 SL보다 작기 때문입니다.
CPSL, SL 및 FL의 라운드당 훈련 대기 시간은 각각 3.78초, 13.90초 및 33.43초입니다.
Uploaded by N2T